
Introduction
In the ever-evolving landscape of Αrtificial Ιntelligence (ΑΙ), Large Language Models (LLMs) have taken the spotlight, showcasing impressive capabilities across a myriad of tasks.
However, when it comes to downstream tasks such as classification and retrieval, smaller, fine-tuned models can sometimes deliver competitive results or even outperform their larger counterparts.
This article delves into the comparative performance of LLMs versus a lower-parameter sentence-transformer fine-tuning framework, SetFit, in classifying domain-specific customer-agent dialogs.
Task description
We aim to perform multi-label classification on customer-agent interactions, sourced from both chat and transcribed audio. This involves handling language intricacies, unbalanced data, and limited annotations.
Dataset
Our dataset is divided into a training set (1056 samples), a validation set (147 samples), and a test set (174 samples) with an average dialog length of 1037 tokens. Our analysis spans chat messages and transcribed audio calls, focusing on 16 distinct topics. As a multi-label classification problem, each dialog can be associated with zero, one, or multiple issues.
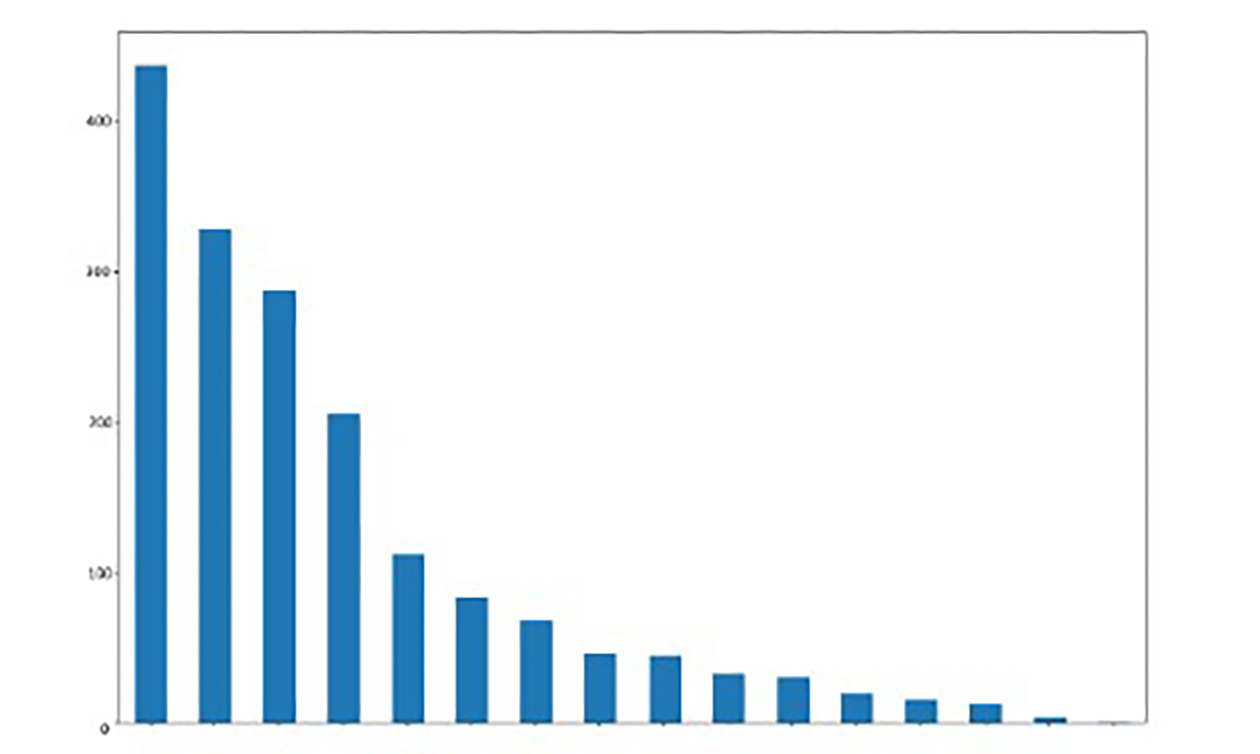
Dataset Class distributions
The primary challenges include:
- Limited labeled samples,
- Highly unbalanced classes (ranging from 438 to just 1 dialogue per class),
- low-resource language data (Greek), and
- noisy data: anonymized content, Greeklish (Greek written in Latin characters), misspellings, and transcription errors.
Method 1: SetFit
To address the data limitations and class imbalance, we fine-tuned a Greek BERT model using SetFit, an efficient and prompt-free framework for few-shot fine-tuning. SetFit consists of two main phases:
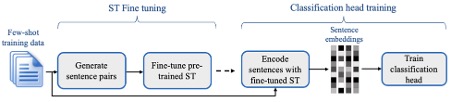
SETFIT ’s fine-tuning and training block diagram (source: SetFit paper)
1. Embedding fine-tuning phase:
This phase aims to fine-tune a Sentence Transformers embedding model to produce embeddings that are more useful for our specific classification task. Although many sentence transformers are adept at Semantic Textual Similarity (STS), they may not initially be well-suited for domain-specific classification.
SetFit addresses this by employing contrastive learning. This involves creating positive and negative pairs of sentences based on their class labels. During the training, the model adjusts its weights to make embeddings of positive pairs more similar and those of negative pairs less similar. This technique is efficient even with few samples, as it creates many unique pairs, thus enhancing the model’s ability to discern fine-grained differences in domain-specific contexts.
2. Classifier training phase:
Once the embedding model is fine-tuned, the next phase involves training the classifier. This phase aims to map the sentence embeddings to the predefined classes accurately. Unlike the embedding fine-tuning phase, classifier training uses the labeled samples directly without creating pairs. The training sentences are first transformed into embeddings using the fine-tuned model, and then these embeddings are used to train the classification head.
Additional optimizations
For dialogs exceeding the model’s limited 512-token maximum sequence length, we used the first 256 tokens of the dialog and 256 tokens from sentences with the highest TF-IDF scores. Additionally, hyperparameter optimization is conducted using the validation set to fine-tune performance.
Method 2: LLMs
We tested the ability of LLMs to understand domain-specific contexts through two methods:
- Zero-shot classification: As a prompt, we provided the list of topics with brief descriptions and common phrases associated with each. The models tried were GPT-4o, GPT-4o mini, GPT 3.5 Turbo, and Claude 3.5 Sonnet.
{
“messages”: [
{
“role”: “system”,
“content”: “You will be provided with a conversation of {generic_dialog_specifications}. Your task is to perform topic classification based on the following topics: {topic_descriptions}”
},
{
“role”: “user”,
“content”: “{dialog_text}”
},
{
“role”: “assistant”,
“content”: “[‘{topic_1}’, ‘{topic_2}’]”
}
]
}
2. Fine-tuning: For GPT-4o mini, we experimented with fine-tuning as a way to instill domain knowledge into the model in two ways:
- Labeled samples: Which human-annotated examples formatted as above are provided as the fine-tuning dataset.
- Pseudo-Completion: Because the finetuning API doesn’t support a completion format for instruction models, we adapt the examples into a pseudo-completion format. In this case, we are using a prompt describing the domain and type of conversation, and an assistant response containing a dialog from the corpus. This aims to introduce domain-specific terms to the model in a way that is easily scalable and doesn’t require human annotations.
{
“messages”: [
{
“role”: “user”,
“content”: “Generate a user/agent conversation of {generic_dialog_specifications}”
},
{
“role”: “assistant”,
“content”: “{dialog_text}”
}
]
}
Prompt refinement
After the first evaluation, weak points were detected. To rework the prompt, we used samples outside the test set and found instances where the prediction didn’t match the human annotations. Topic descriptions were enriched with additional examples and better clarity until those instances could be consistently classified correctly.
Evaluation
Here’s how the models performed:
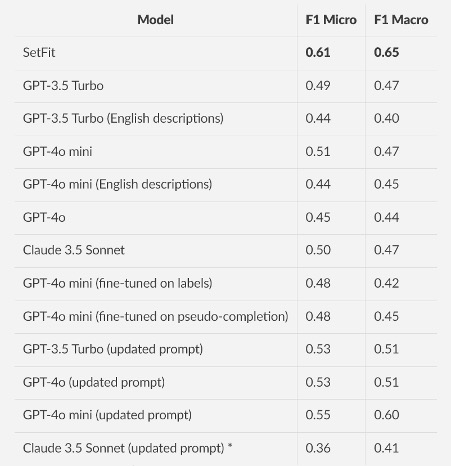
Performance of the models.
* The updated prompt results for Claude Sonnet 3.5 can be misleading since the prompt was refined only on GPT outputs.
Analysis
LLMs
- Language matters: Keeping topic descriptions in Greek improved performance, likely due to better alignment with the conversation language. Matching the language of the conversations means there is less information lost in the cross-lingual representation of the tokens.
- Larger LLM underperformance: Surprisingly, GPT-4ο and Claude 3.5 Sonnet didn’t always outperform smaller models, suggesting that extensive general knowledge may not benefit specific tasks.
- Finetuning limits: Incremental data finetuning didn’t enhance results in a way that would encourage scaling it further. This aligns with the broader view that finetuning is more commonly used for stylistic adjustments than new knowledge infusion.
SetFit vs. LLMs
- Specialized training: A fine-tuned SetFit model, even with limited data, can outperform LLMs in specialized tasks. This could be attributed to the subtleties and edge cases of the annotation process and the inherent subjectivity of the annotator. The fine-tuned model has been trained to learn such patterns, while an LLM relies on the accumulated knowledge of its extensive pretraining data. The drop in performance when using GPT-4o compared to GPT-4o mini could suggest that this greater general knowledge is not helpful for this task.
- Language resources: The drop in performance when using English topic descriptions in combination with Greek dialogs indicates potential struggles with low-resource languages and that an all-English dataset might yield better results.
- Prompt engineering: Exploring further prompt engineering can greatly enhance model performance, as seen in our second round of GPT experiments. While using few-shot prompting would be difficult because of the conversational nature of the dataset, and the wide range of sub-topics that may be included in a topic, techniques like Chain-of-Thought and additional prompt refinement cycles are worth investigating.
- Cost: After the initial annotation cost, the operational costs for running sentence-transformer models are significantly lower, making them a cost-effective solution for long-term deployment in resource-constrained environments. However, as the cost of LLMs continues to decrease, they are becoming increasingly accessible.
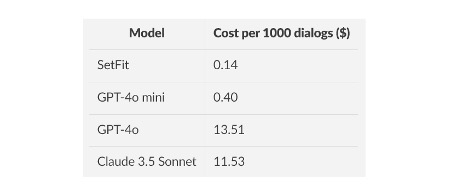
For the SetFit model, a worst-case scenario cost was estimated using the VM cost for the total runtime of 1000 dialogs without input batching. The LLM costs were approximated using the number of input and output tokens of the test set for each, scaled to 1000 dialogs.
Conclusion
Our study underscores the significant potential of fine-tuned smaller models in tackling domain-specific tasks effectively. While LLMs offer unparalleled versatility and broad applicability, their performance is closely tied to the language and specificity of the task at hand.
On the other hand, SetFit, with its efficient fine-tuning and prompt-free framework, emerges as a powerful contender, particularly in specialized domains. The results suggest that despite the rapid advancements and decreasing costs associated with LLMs, specialized training on smaller models remains a cost-effective and potent solution for specific applications